ARA-C01 Lernressourcen & ARA-C01 Pruefungssimulationen
Wiki Article
Übrigens, Sie können die vollständige Version der Fast2test ARA-C01 Prüfungsfragen aus dem Cloud-Speicher herunterladen: https://drive.google.com/open?id=1Th7km6FMw2vOfz5mD-LoaYN17MIpPFzA
Wenn Sie Fast2test wählen, steht der Erfolg schon vor der Tür. Und bald können Sie Snowflake ARA-C01 Zertifikat bekommen. Das Produkt von Fast2test bietet Ihnen 100%-Pass-Garantie und auch einen kostenlosen einjährigen Update-Service.
Die Snowflake ARA-C01 (SnowPro Advanced Architect Certification) Zertifizierungsprüfung ist eine cloudbasierte Zertifizierungsprüfung, die darauf ausgelegt ist, die fortgeschrittenen Fähigkeiten und Kenntnisse von Snowflake-Architekten zu validieren. Diese Zertifizierungsprüfung richtet sich an Fachleute, die ein tiefes Verständnis von Snowflake-Datenlagern und ihrer Architektur besitzen und komplexe Snowflake-Lösungen unter Verwendung bewährter Verfahren entwerfen und implementieren können. Die SnowPro Advanced Architect Certification Exam ist eine herstellerneutrale Zertifizierung, was bedeutet, dass sie nicht mit einem bestimmten Anbieter oder einer bestimmten Technologie verbunden ist.
ARA-C01 Pruefungssimulationen, ARA-C01 PDF
Um immer die besten IT-Zertifizierung Dumps für Sie zu bieten, verbessern wir Fast2test immer die Qualität der Snowflake ARA-C01 Dumps und aktualisieren sie nach den neuesten Prüfungsvorschriften. Fast2test ist Ihre beste Wahl auf dem heutigen Markt. Wenn Sie nicht glauben, können Sie nach anderen erkündigen. Es gibt unbedingt jemanden, der unsere Fast2test Prüfungsunterlagen früher benutzt hat. Wir versprechen Ihnen die beste Nachschläge, einmal die Snowflake ARA-C01 Prüfung zu bestehen.
Die Snowflake ARA-C01-Zertifizierung wird von Branchenführern anerkannt und ist ein wertvolles Gut für Fachleute, die ihre Karriere im Cloud Computing vorantreiben möchten. Dies ist eine hervorragende Möglichkeit, Ihr Know -how in Snowflake zu demonstrieren und neue Karrieremöglichkeiten zu eröffnen. Die Zertifizierung ist auch ein Beweis für Ihr Engagement, über die neuesten Branchentrends und -technologien auf dem Laufenden zu bleiben.
Snowflake SnowPro Advanced Architect Certification ARA-C01 Prüfungsfragen mit Lösungen (Q106-Q111):
106. Frage
A table, EMP_ TBL has three records as shown: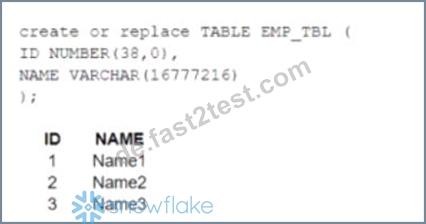
The following variables are set for the session:
Which SELECT statements will retrieve all three records? (Select TWO).
- A. Select * FROM Stbl_ref WHERE Scol_ref IN ('Name1','Nam2','Name3');
- B. SELECT * FROM EMP_TBL WHERE identifier(Scol_ref) IN ('Namel','Name2', 'Name3');
- C. SELECT * FROM identifier($tbl_ref) WHERE ID IN Cvarl','var2','var3');
- D. SELECT * FROM $tb1_ref WHERE $col_ref IN ($var1, Svar2, Svar3);
- E. SELECT * FROM identifier<Stbl_ref> WHERE NAME IN ($var1, $var2, $var3);
Antwort: B,D
Begründung:
* The correct answer is B and E because they use the correct syntax and values for the identifier function and the session variables.
* The identifier function allows you to use a variable or expression as an identifier (such as a table name or column name) in a SQL statement. It takes a single argument and returns it as an identifier. For example, identifier($tbl_ref) returns EMP_TBL as an identifier.
* The session variables are set using the SET command and can be referenced using the $ sign. For example, $var1 returns Name1 as a value.
* Option A is incorrect because it uses Stbl_ref and Scol_ref, which are not valid session variables or identifiers. They should be $tbl_ref and $col_ref instead.
* Option C is incorrect because it uses identifier<Stbl_ref>, which is not a valid syntax for the identifier function. It should be identifier($tbl_ref) instead.
* Option D is incorrect because it uses Cvarl, var2, and var3, which are not valid session variables or values. They should be $var1, $var2, and $var3 instead. References:
* Snowflake Documentation: Identifier Function
* Snowflake Documentation: Session Variables
* Snowflake Learning: SnowPro Advanced: Architect Exam Study Guide
107. Frage
An Architect is designing a pipeline to stream event data into Snowflake using the Snowflake Kafka connector. The Architect's highest priority is to configure the connector to stream data in the MOST cost-effective manner.
Which of the following is recommended for optimizing the cost associated with the Snowflake Kafka connector?
- A. Utilize a higher Buffer.flush.time in the connector configuration.
- B. Utilize a higher Buffer.size.bytes in the connector configuration.
- C. Utilize a lower Buffer.count.records in the connector configuration.
- D. Utilize a lower Buffer.size.bytes in the connector configuration.
Antwort: A
Begründung:
The minimum value supported for the buffer.flush.time property is 1 (in seconds). For higher average data flow rates, we suggest that you decrease the default value for improved latency. If cost is a greater concern than latency, you could increase the buffer flush time. Be careful to flush the Kafka memory buffer before it becomes full to avoid out of memory exceptions.
https://docs.snowflake.com/en/user-guide/data-load-snowpipe-streaming-kafka
108. Frage
A table for IOT devices that measures water usage is created. The table quickly becomes large and contains more than 2 billion rows.
The general query patterns for the table are:
1. DeviceId, lOT_timestamp and Customerld are frequently used in the filter predicate for the select statement
2. The columns City and DeviceManuf acturer are often retrieved
3. There is often a count on Uniqueld
Which field(s) should be used for the clustering key?
- A. Deviceld and Customerld
- B. City and DeviceManuf acturer
- C. lOT_timestamp
- D. Uniqueld
Antwort: A
Begründung:
A clustering key is a subset of columns or expressions that are used to co-locate the data in the same micro-partitions, which are the units of storage in Snowflake. Clustering can improve the performance of queries that filter on the clustering key columns, as it reduces the amount of data that needs to be scanned. The best choice for a clustering key depends on the query patterns and the data distribution in the table. In this case, the columns DeviceId, IOT_timestamp, and CustomerId are frequently used in the filter predicate for the select statement, which means they are good candidates for the clustering key. The columns City and DeviceManufacturer are often retrieved, but not filtered on, so they are not as important for the clustering key.
The column UniqueId is used for counting, but it is not a good choice for the clustering key, as it is likely to have a high cardinality and a uniform distribution, which means it will not help to co-locate the data.
Therefore, the best option is to use DeviceId and CustomerId as the clustering key, as they can help to prune the micro-partitions and speed up the queries. References: Clustering Keys & Clustered Tables, Micro-partitions & Data Clustering, A Complete Guide to Snowflake Clustering
109. Frage
Which of the following ingestion methods can be used to load near real-time data by using the messaging services provided by a cloud provider?
- A. Snowflake streams
- B. Snowpipe
- C. Snowflake Connector for Kafka
- D. Spark
Antwort: B
110. Frage
A company is trying to Ingest 10 TB of CSV data into a Snowflake table using Snowpipe as part of Its migration from a legacy database platform. The records need to be ingested in the MOST performant and cost-effective way.
How can these requirements be met?
- A. Use ON_ERROR = continue in the copy into command.
- B. Use purge = TRUE in the copy into command.
- C. Use FURGE = FALSE in the copy into command.
- D. Use on error = SKIP_FILE in the copy into command.
Antwort: D
Begründung:
For ingesting a large volume of CSV data into Snowflake using Snowpipe, especially for a substantial amount like 10 TB, the on error = SKIP_FILE option in the COPY INTO command can be highly effective. This approach allows Snowpipe to skip over files that cause errors during the ingestion process, thereby not halting or significantly slowing down the overall data load. It helps in maintaining performance and cost-effectiveness by avoiding the reprocessing of problematic files and continuing with the ingestion of other data.
111. Frage
......
ARA-C01 Pruefungssimulationen: https://de.fast2test.com/ARA-C01-premium-file.html
- ARA-C01 Deutsch ???? ARA-C01 Examengine ???? ARA-C01 Examsfragen ???? ▶ www.zertpruefung.de ◀ ist die beste Webseite um den kostenlosen Download von “ ARA-C01 ” zu erhalten ????ARA-C01 Prüfungsübungen
- ARA-C01 Ressourcen Prüfung - ARA-C01 Prüfungsguide - ARA-C01 Beste Fragen ???? Erhalten Sie den kostenlosen Download von ⏩ ARA-C01 ⏪ mühelos über ( www.itzert.com ) ????ARA-C01 Examsfragen
- ARA-C01 Ressourcen Prüfung - ARA-C01 Prüfungsguide - ARA-C01 Beste Fragen ⏫ Öffnen Sie die Webseite ☀ www.zertpruefung.ch ️☀️ und suchen Sie nach kostenloser Download von ▷ ARA-C01 ◁ ????ARA-C01 Prüfungs
- ARA-C01 Exam Fragen ???? ARA-C01 Exam ☔ ARA-C01 Fragen Beantworten ???? Öffnen Sie { www.itzert.com } geben Sie ☀ ARA-C01 ️☀️ ein und erhalten Sie den kostenlosen Download ????ARA-C01 Testantworten
- ARA-C01 Fragen Beantworten ???? ARA-C01 Zertifizierung ???? ARA-C01 Zertifizierung ???? Sie müssen nur zu ▛ www.itzert.com ▟ gehen um nach kostenloser Download von 【 ARA-C01 】 zu suchen ????ARA-C01 Lerntipps
- ARA-C01 Deutsch Prüfungsfragen ???? ARA-C01 Prüfungsübungen ???? ARA-C01 Deutsch Prüfungsfragen ???? Öffnen Sie die Webseite ( www.itzert.com ) und suchen Sie nach kostenloser Download von ➽ ARA-C01 ???? ☘ARA-C01 Prüfungs
- ARA-C01 Deutsch ???? ARA-C01 Testantworten ???? ARA-C01 Zertifizierung ???? Suchen Sie auf der Webseite { www.zertfragen.com } nach “ ARA-C01 ” und laden Sie es kostenlos herunter ????ARA-C01 Zertifizierung
- ARA-C01 Mit Hilfe von uns können Sie bedeutendes Zertifikat der ARA-C01 einfach erhalten! ???? Suchen Sie einfach auf ☀ www.itzert.com ️☀️ nach kostenloser Download von 《 ARA-C01 》 ????ARA-C01 Lerntipps
- ARA-C01 Deutsch Prüfungsfragen ⬅ ARA-C01 Unterlage ???? ARA-C01 Ausbildungsressourcen ???? Suchen Sie auf der Webseite 【 www.pass4test.de 】 nach 【 ARA-C01 】 und laden Sie es kostenlos herunter ????ARA-C01 Praxisprüfung
- Kostenlos ARA-C01 dumps torrent - Snowflake ARA-C01 Prüfung prep - ARA-C01 examcollection braindumps ???? URL kopieren ⮆ www.itzert.com ⮄ Öffnen und suchen Sie ➠ ARA-C01 ???? Kostenloser Download ????ARA-C01 Zertifizierungsantworten
- ARA-C01 Deutsche ???? ARA-C01 Unterlage ???? ARA-C01 Unterlage ???? URL kopieren ⏩ www.zertsoft.com ⏪ Öffnen und suchen Sie ▷ ARA-C01 ◁ Kostenloser Download ????ARA-C01 Examsfragen
- www.stes.tyc.edu.tw, joshpsgk012665.blogrenanda.com, www.stes.tyc.edu.tw, www.stes.tyc.edu.tw, bookmarkproduct.com, ariabookmarks.com, zaynwllu583136.bloggerswise.com, shaniaiwwm454357.bleepblogs.com, oisiwyto307795.blogs100.com, barrysxnu552417.wikitron.com, Disposable vapes
BONUS!!! Laden Sie die vollständige Version der Fast2test ARA-C01 Prüfungsfragen kostenlos herunter: https://drive.google.com/open?id=1Th7km6FMw2vOfz5mD-LoaYN17MIpPFzA
Report this wiki page